Serial Jobs
Videos
Videos of this topic may be available from one of our kickstart course playlists: 2025 summer, 2025 winter, 2024, 2023, 2022 Summer, 2022 February, 2021 Summer, 2021 February. Or see computing explained with HPC kitchen.
Abstract
Batch scripts let you run work non-interactively, which is important for scaling. You create a batch script, which runs in the background. You come back later and see the results.
Example batch script, submit with
sbatch the_script.sh:#!/bin/bash -l #SBATCH --time=01:00:00 #SBATCH --mem=4G # Run your code here python my_script.py
See the quick reference for complete list of options.
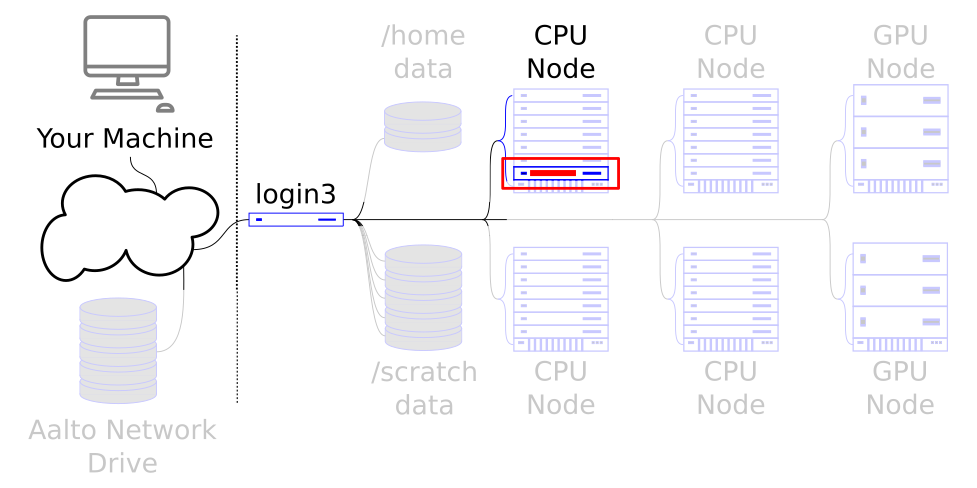
This tutorial covers the basics of serial jobs. With what you are learning so far, you can control a small amount of power of the cluster.
Prerequisites
Why batch scripts?
You learned, in Slurm: the queuing system, how all Triton users must do their computation by submitting jobs to the Slurm batch system to ensure efficient resource sharing. This lets you run many things at once without having to watch each one separately - the true power of the cluster.
A batch script is simply a shell script (remember Using the cluster from a command line?), where you put your resource requests and job steps.
Your first job script
A job script is simply a shell script (Bash). And so the first line in
the script should be the shebang directive (#!)
followed by the full path to the executable binary of the shell’s
interpreter, which is Bash in our case. What then follow are the
resource requests, and then the job steps.
Let’s take a look at the following script
#!/bin/bash
#SBATCH --time=00:05:00
#SBATCH --mem=100M
#SBATCH --output=pi.out
echo "Hello $USER! You are on node $HOSTNAME. The time is $(date)."
# For the next line to work, you need to be in the
# hpc-examples directory.
srun python3 slurm/pi.py 10000
Let’s name it run-pi.sh (create a file using your editor of choice,
e.g. nano; write the script above and save it)
The symbol # is a comment in the bash script, and Slurm
understands #SBATCH as parameters, determining the resource
requests. Here, we have requested a time limit of 5 minutes, along
with 100 MB of RAM.
Resource requests are followed by job steps, which are the actual
tasks to be done. Each srun within the a slurm script is a job
step, and appears as a separate row in your history - which is useful
for monitoring.
Having written the script, you need to submit the job to Slum through
the sbatch command. Since the command is python slurm/pi.py,
you need to be in the hpc-examples directory from our sample
project:
$ cd hpc-examples # wherever you have hpc-examples
$ sbatch run-pi.sh
Submitted batch job 52428672
Warning
You must use sbatch, not bash to submit the job since it is
Slurm that understands the SBATCH directives, not Bash.
When the job enters the queue successfully, the response that the job has been submitted is printed in your terminal, along with the jobid assigned to the job.
You can check the status of you jobs using slurm q/slurm queue (or
squeue -u $USER):
$ slurm q
JOBID PARTITION NAME TIME START_TIME STATE NODELIST(REASON)
52428672 debug run-pi.sh 0:00 N/A PENDING (None)
Once the job is completed successfully, the state changes to
COMPLETED and the output is then saved to pi.out in the
current directory. You can also wildcards like %u for your
username and %j for the jobid in the output file name. See the
documentation of sbatch
for a full list of available wildcards.
Setting resource parameters
The resources were discussed in Slurm: the queuing system, and barely need to be
mentioned again here - the point is they are the same. For example,
you might use --mem=5G or --time=5:00:00. Always keep the
reference page close for looking these up.
Checking your jobs
Once you submit your jobs, it goes into a queue. The two most useful
commands to see the status of your jobs with are slurm q/slurm
queue and slurm h/slurm history (or squeue -u $USER and
sacct -u $USER).
More information is in the monitoring tutorial.
Cancelling a job
You can cancel jobs with scancel JOBID. To obtain job id, use the
monitoring commands.
Full reference
The reference page contains it all, or expand it below.
Slurm quick ref
Command |
Description |
|---|---|
|
submit a job to queue (see standard options below) |
|
Within a running job script/environment: Run code using the allocated resources (see options below) |
|
On frontend: submit to queue, wait until done, show output. (see options below) |
|
Submit job, wait, provide shell on node for interactive playing (X forwarding works, default partition interactive). Exit shell when done. (see options below) |
|
(advanced) Another way to run interactive jobs, no X forwarding but simpler. Exit shell when done. |
|
Cancel a job in queue |
|
(advanced) Allocate resources from frontend node. Use |
|
View/modify job and slurm configuration |
Command |
Option |
Description |
|---|---|---|
|
|
time limit |
|
time limit, days-hours |
|
|
job partition. Usually leave off and things are auto-detected. |
|
|
request N MB of memory per core |
|
|
request N MB memory per node |
|
|
Allocate *n* CPU’s for each task. For multithreaded jobs. (compare ``–ntasks``: ``-c`` means the number of cores for each process started.) |
|
|
allocate minimum of N, maximum of M nodes. |
|
|
allocate resources for and start n tasks (one task=one process started, it is up to you to make them communicate. However the main script runs only on first node, the sub-processes run with “srun” are run this many times.) |
|
|
request a GPU, or |
|
|
request GPUs with at least |
|
|
request GPUs with CUDA compute capability of at least N.N. See above for combining with other GRES. |
|
|
short job name |
|
|
print output into file output |
|
|
print errors into file error |
|
|
allocate exclusive access to nodes. For large parallel jobs. |
|
|
request feature (see |
|
|
request a node with a local disk storage space and |
|
|
Run job multiple times, use variable |
|
|
notify of events: |
|
|
Aalto email to send the notification about the job. External email addresses doesn’t work. |
|
|
|
Print allocated nodes (from within script) |
Exercises
The scripts you need for the following exercises can be found in our
hpc-examples, which
we discussed in Using the cluster from a command line (section
Copy your code to the cluster).
You can clone the repository by running
git clone https://github.com/AaltoSciComp/hpc-examples.git. Doing this
creates you a local copy of the repository in your current working
directory. This repository will be used for most of the tutorial exercises.
Serial-1: Basic batch job
Submit a batch job that just runs hostname and pi.py.
Remember to give pi.py some number of iterations as an argument.
Set time to 1 hour and 15 minutes, memory to 500MB.
Change the job’s name and output file.
Check the output. Does the printed hostname match the one given by
slurm history/sacct -u $USER?
Solution
Output from hostname should match the node in slurm history.
Sbatch first assigns you a node depending on your requested resources,
and then runs all commands included in the script.
Part of a series: ngrams:
Serial-2: Compute ngrams via a batch jobs
Create a batch job that computes our ngrams.
Solution
Create a script file ngrams.sh with the nano editor:
$ nano ngrams.sh
#!/bin/bash
#SBATCH --time=00:05:00
#SBATCH --mem=1G
srun python3 ngrams/count.py /scratch/shareddata/teaching/gutenberg-fiction/Gutenberg-Fiction-first100.zip -o ngrams2 -n 2
We submit with:
$ sbatch ngrams.sh
Part of a series: pi:
Serial-3: Submitting and cancelling a job
Create a batch script which does nothing (or some pointless
operation for a while), for example sleep 300 (this shell
command does nothing for 300 seconds). Check the queue to see when
it starts running. Then, cancel the job. What output is produced?
Solution
You can check when your job starts running with slurm q. Then
you can cancel it with scancel JOBID, where JOBID can be found
from slurm q output. After cancelling the job, it should still produce
an output file (named either slurm-JOBID.out or whatever you defined in the
#!/bin/bash
echo "We are waiting"
sleep 300
echo "We are done waiting"
srun python3 slurm/pi.py 1000000
You can check when your job starts running with slurm q. Then
you can cancel it with scancel JOBID, where JOBID can be found
from slurm q output. After cancelling the job, it should still produce
an output file (named either slurm-JOBID.out or whatever you defined in the
sbatch file.) The output file also says the job was cancelled.
Serial-4: Modifying Slurm script while its running
Modifying scripts while a job has been submitted is a bad practice.
Add sleep 120 into the Slurm script that runs pi.py. Submit the
script and while it is running, open the Slurm script with an editor of your
choice and add the following line near the end of the script.
echo 'Modified'
Use slurm q to check when the job finishes and check the output. What
can you interpret from this?
Remove the created line after you have finished.
Solution
In this case we modified a script after we had submitted it. These modifications do not affect the script that is in the queue as that script has already been given to Slurm.
The Slurm script is locked in place when you submit a script. Modifications to the script do not affect the script that is being run.
You should always make certain that you do not modify the Slurm script being run or you cannot replicate your run.
Serial-5: Modify script while it is running
Modifying scripts while a job has been submitted is a bad practice.
Add sleep 180 into the Slurm script that runs pi.py. Submit the
script and while it is running, open the pi.py with an editor of your
choice and add the following line near the start of the script.
raise Exception()
Use slurm q to check when the job finishes and check the output. What
can you interpret from this?
Remove the created line after you have finished. You can also use
git checkout -- pi.py (remember to give a proper relative path,
depending on your current working directory!)
Solution
In this case we modified the Python code before it had begun executing
(we added a line that raised an error while the sleep 180 was being
executed).
The code that the Slurm script executes will be determined when the script is running. It is not locked in place when you submit a script.
You should always make certain that you do not modify the code that the Slurm script will execute while it is queued or while its being run.
Otherwise you can get errors and you cannot replicate your run.
Serial-6: Checking output
You can look at the output of files as your program is running. Let’s demonstrate.
Create a slurm script that runs the following program. This is a shell script which, every 10 seconds (for 30 iterations), prints the date:
for i in $(seq 30); do
date
sleep 10
done
Submit the job to the queue.
Log out from Triton. Log back in and use
slurm queue/squeue -u $USERto check the job status.Use
cat NAME_OF_OUTPUTFILEto check at the output periodically. You can usetail -f NAME_OF_OUTPUTFILEto view the progress in real time as new lines are added (Control-C to cancel)Cancel the job once you’re finished.
Solution
#!/bin/bash
#SBATCH --output test-check-output.out
for i in $(seq 30); do
date
sleep 10
done
We note that a new line appears about every 10 seconds. Note that the delays might happen because of buffering, as the system tries to avoid doing too many small i/o operations:
$ tail -f test-check-output.out
Wed 7 Jun 10:49:58 EEST 2023
Wed 7 Jun 10:50:08 EEST 2023
(more every 10 seconds)
Serial-7: Constrain to a certain CPU architecture
Modify the script from exercise #1 to run on only one type of CPU
using the --constraint option. Hint: check Triton quick reference
Solution
Simply add #SBATCH --constraint=X to your sbatch script, or
give --constraint=X to srun as additional argument. For example,
to run only on Haswell cpu’s you can add --constraint=hsw, or
similarily for amd milan cpus --constraint=milan. This also
works identically for gpus.
Serial-8: Why you use sbatch, not bash.
(Advanced) What happens if you submit a batch script with bash
instead of sbatch? Does it appear to run? Does it use all the
Slurm options?
Solution
It looks like it runs, but actually is only running on the login
node! If you used srun python3 slurm/pi.py 10000, then it
would request a Slurm allocation, but not use any of the
#SBATCH parameters, so might not request the resources you
need.:
$ bash run-pi.sh
Calculating Pi via 10000 stochastic trials
{"successes": 7815, "pi_estimate": 3.126, "iterations": 10000}
(advanced) Serial-9: Interpreters other than bash
(Advanced) Create a batch script that runs in another language
using a different #! line.
Does it run? What are some of the advantages and problems here?
Solution
Using other language to run your sbatch script is entirely possible.
For example if you are more used to writing scripts on zsh compared to bash,
you could use #!/bin/zsh. You could even use something completely
different from a shell. For example using #!/usr/bin/env python3
would let you write python code directly in the sbatch script. This is
mostly an interesting curiosity however and is not usually practical.
(advanced) Serial-10: Job environment variables.
Either make a sbatch script that runs the command env | sort, or
use srun env | sort. The env utility prints all
environment variables, and sort sorts it (and | connects
the output of env to the input of sort.)
This will show all of the environment variables that are set in the
job. Note the ones that start with SLURM_. Notice how they
reflect the job parameters. You can use these in your jobs if
needed (for example, a job that will adapt to the number of
allocated CPUs).
What’s next?
There are various tools one can use to do job monitoring.