Slurm: the queuing system
Videos
Videos of this topic may be available from one of our kickstart course playlists: 2025 summer, 2025 winter, 2024, 2023, 2022 Summer, 2022 February, 2021 Summer, 2021 February. Or see computing explained with HPC kitchen.
Abstract
Slurm knows of all resources (compute nodes) and all resource requests (job submissions), and tries to schedule jobs to the nodes as efficiently as possible.
Available resources include CPUs, memory, GPUs, and time. For information on how to request these, see Triton quick reference.
How do you know how many resources to request? Usually you start with some guess, and increase/decrease based on monitoring of the job.
What is a cluster?
Triton is a large system that combines many different individual computer nodes. Hundreds of people are using Triton simultaneously. Thus resources (CPU time, memory, etc.) need to be shared among everyone.
This resource sharing is done by a software called a job scheduler or workload manager, and Triton’s workload manager is Slurm (which is also the dominant in the world one these days). Triton users submit jobs which are then scheduled and allocated resources by the workload manager.
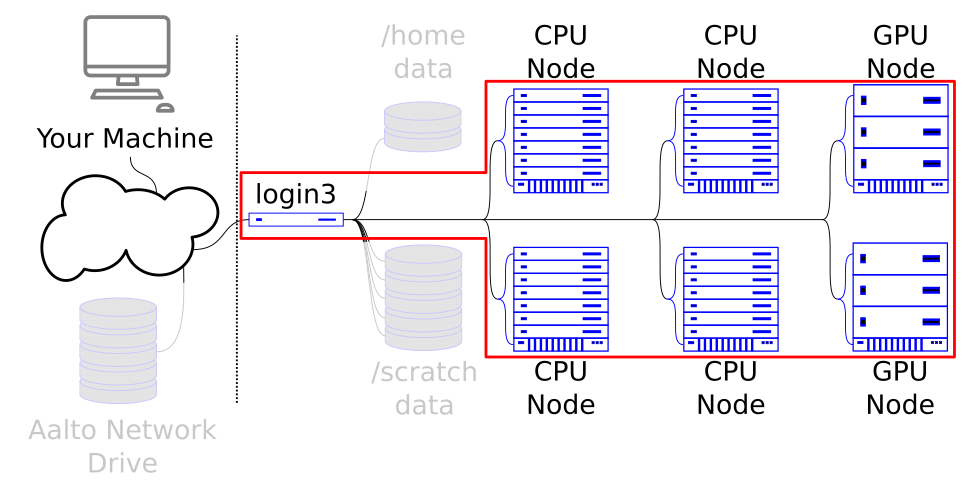
Slurm allows you to control all of the computing power from the login node.
An analogy: the HPC Diner
You’re eating out at the HPC Diner. What happens when you arrive?
Scheduling resources
A host greets you and takes your party size and estimated dining time. You are given a number and asked to wait a bit.
The host looks at who is currently waiting and makes a plan.
If you are two people, you might squeeze in soon.
If you are a lot of people, the host will try to slowly free up enough tables to join to eat together.
If you are a really large party, you might need an advance reservation (or have to wait a really long time).
Groups are called when it is their turn.
Resources (tables) are used as efficiently as possible
Cooking in the background
You don’t use your time to cook yourself.
You make an order. It goes to the back and gets cooked (possibly a lot at once!), and you can do something else.
Your food comes out when ready and you can check the results.
Asynchronous execution allows more efficient dining.
Thanks to HPC Carpentry / Sabry Razick for the idea.
The basic process
You have your program mostly working
You decide what resources you want
You ask Slurm to give you those resources
You might say “run this and let me know when done”, this is covered later in Serial Jobs.
You might want those resources to play around yourself. This is covered next in Interactive jobs.
If you are doing the first one, you come back later and check the output files.
The resources Slurm manages
Slurm comes with a multitude of parameters which you can specify to ensure you will be allocated enough memory, CPU cores, time, etc.

Imagine resource requests as boxes of a requested number of CPUs, memory, time, and any other resources requested. The smaller the box, the more likely you can get scheduled soon.
The basic resources are:
Time: While not exactly a resources, you need to specify the expacted usage time (run time) of each job for scheduling purposes. If you go over by too much, your job will be killed. This is
--time, for example--time=DAYS-HH:MM:SS.Memory: Memory is needed for data in jobs. If you run out of processors, your job is slow, but if you run out of memory, then everything dies. This is
--memor--mem-per-cpu.CPUs (also known as “processors” or “(processor) cores”): Processor cores. This resource lets you do things in parallel the classic way, by adding processors. Depending on how the parallelism works, there are different ways to request the CPUs - see Parallel computing: different methods explained. CPUs. This is
--cpus-per-taskand--ntasks, but you must read that page before using these!GPUs: Graphical Processing Units are modern, highly parallel compute units. We will discuss requesting them in GPU computing.
If you did even larger work on larger clusters, input/output bandwidth and licenses are also possible resources.
The more resources you request, the lower your priority will be in the future. So be careful what you request!
See also
As always, the Triton quick reference lists all the options you need.
Other submission parameters
We won’t go into them, but there are other parameters that tell Slurm what to do. For example, you could request to only run on the latest CPU architecture. You could say you want a node all to yourself. And so on.
How many resources to request?
See also
This is one of the most fundamental questions:
You want to request enough resources, so that your code actually runs.
You don’t want to request too much, since it is wasteful and lowers your priority in the future.
Basically, people usually start by guessing and request more than you
think you need at the start for testing. Check what you have
actually used (Triton: slurm history), and adjust the requests to
match.
The general rule of thumb is to request the least possible, so that your stuff can run faster. That is because the less you request, the faster you are likely to be allocated resources. If you request something slightly less than a node size (note that we have different size nodes) or partition limit, you are more likely to fit into a spare spot.
For example, we have many nodes with 12 cores, and some with 20 or 24. If you request 24 cores, you have very limited options. However, you are more likely to be allocated a node if you request 10 cores. The same applies to memory: most common cutoffs are 48, 64, 128, 256GB. It’s best to use smaller values when submitting interactive jobs, and more for batch scripts.
Partitions
A slurm partition is a set of computing nodes dedicated to a specific purpose. Examples include partitions assigned to debugging(“debug” partition), batch processing(“batch” partition), GPUs(“gpu” partition), etc.
On Triton, you don’t need to worry about partitions most of the time - they are automatically set. You might need partition in several cases though:
--partition interactivegives you some settings optimized for interactive work (where things aren’t running constantly).
On other clusters, you might need to set a partition sometimes.
Command sinfo -s lists a summary of the available partitions. You
can see the purpose and use of our partitions in the quick
reference.
Exercises
Slurm-1: Info commands
Check out some of these commands: sinfo, sinfo -N,
squeue, and squeue -a. These give you some information
about Slurm’s state.
What’s next?
We move on to running interactive jobs.