About clusters and your work
Videos
Videos of this topic may be available from one of our kickstart course playlists: 2025 summer, 2025 winter, 2024, 2023, 2022 Summer, 2022 February, 2021 Summer, 2021 February. Or see computing explained with HPC kitchen.
Abstract
A cluster is a bunch of computers connected together by network, shared storage, and a scheduler (Slurm) that distributes waiting jobs across the available resources.
Triton is the Aalto University cluster and has significant resources and local support.
A cluster needs techniques to use properly - it’s not like your own computer which you have full access to.
Ask for help if you need it.
Keep the Triton quick reference open.
Science-IT is an Aalto infrastructure for scientific computing. Its roots was a collaboration between the Information and Computer Science department (now part of CS), Biomedical Engineering and Computational Science department (now NBE), and Applied Physics department. Now, it still serves all Aalto and is organized from the School of Science.
You are now at the first step of the Triton tutorial.
What is a cluster?
A high-performance computing cluster is basically a lot of computers not that different than your own. While the hardware is not that much more powerful than a typical “power workstation”, it’s special in that there is so much of it and you can use it together. We’ll learn more about how it’s used together later on.
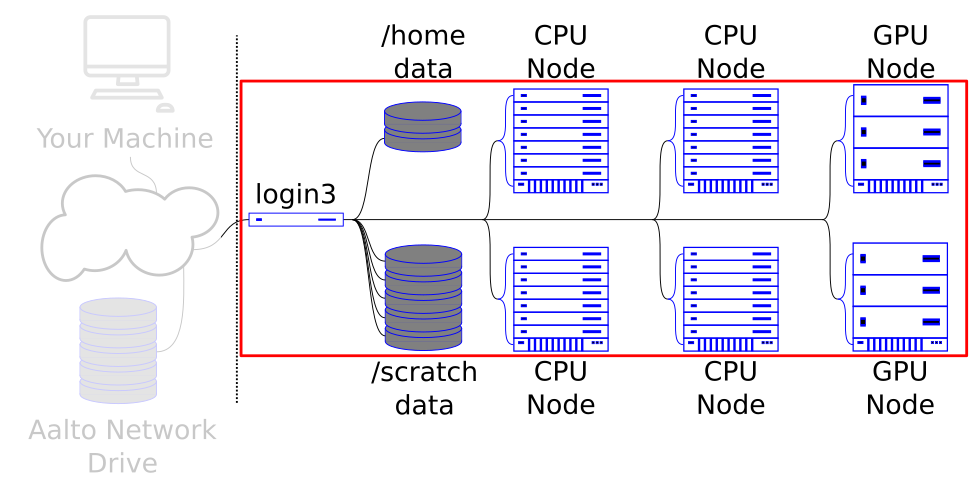
Figure 1: The schematic of our sample cluster. We’ll go through this piece by piece.
The things labeled “CPU Node” and “GPU Node” aren’t quite accurate in real life: that picture better depicts one a whole rack of nodes. But we show it like this so that we can pretend that one row is a CPU later on to illustrate a point.
Cluster workflow
Typical cluster workflow is outlined in the image below:

Figure 2: Example workflow in the cluster.
Each project starts with an initial setup that usually involves getting your code and data into Triton and then installing software needed by the code.
We usually recommend that:
Each project should have a separate folder in the work directory. This makes project management easier.
Big software installations should be done outside of the code repositories. Version control tools and editors often monitor filesystem changes and having installations in the same folder as your code can result in unnecessary traffic towards the file system. It makes uninstallation of programs more difficult as well.
After initial setup most workflows spend a lot of time running and editing the code. The running part is done through the Slurm queue system while the editing part can be done in many different ways.
The image below highlights some of the options you have for editing your code:

Figure 3: Various ways of editing your code in the cluster.
You’ll have to decide which way of editing works for you and your project, but because most of a project’s lifetime is usually spent editing your code and running it, you should keep the following considerations in mind:
What is the easiest way for you to manage your Slurm submission scripts and your jobs?
Do you want to do the changes on your computer and then transfer them to Triton or could you do the changes on Triton in the first place? Which is easier in my case?
How much data do you need to transfer to verify my results? Can you view your results without having to move things around?
Do you need to run the same code in multiple places? Would version control make it easier to synchronize multiple copies?
About Triton
Triton is a mid-sized heterogeneous computational Linux cluster. This means that we are not at a massive scale (though we are, after CSC, the largest publically known known cluster in Finland). We are heterogeneous, so we continually add new hardware and incrementally upgrade. We are designed for scientific computing and data analysis. We use Linux as an operating system (like most supercomputers). We are a cluster: many connected nodes with a scheduling system to divide work between them. The network and some storage is shared, CPUs, memory, and other storage is not shared.
Triton was renewed in May 2024
Triton was completely re-installed and upgraded in May 2024. Anything that worked before has to be updated or reinstalled to work again, and many lesser-used things haven’t been. If you notice something wrong or missing, let us know.
A real Ship of Theseus
In the Ship of Theseus thought experiment, every piece of a ship is incrementally replaced. Is it the same ship or not?
Triton is a literal Ship of Theseus. Over the ~10 years it has existed, every part has been upgraded and replaced, except possibly some random cables and other small parts. Yet, it is still Triton. Most clusters are recycled after a certain lifetime and replaced with a new one.
On an international scale of universities, the power of Triton is relatively high and it has a very diverse range of uses, though CSC has much more. Using this power requires more effort than using your own computer - you will need to get/be comfortable in the shell, using shell scripting, managing software, managing data, and so on. Triton is a good system to use for learning.
Getting help
See also
Main reference: Getting Triton help
First off, realize it is hard to do everything alone - with the diversity of types of computational research and researchers, it’s not even true that everyone should know everything. If you would like to focus on your science and have someone else focus on the computational part, see our Research Software Engineer service. It’s also available for expert consultations.
There are many ways to get help. Most daily questions should go to our issue tracker (direct link), which is hosted on Aalto Gitlab (login with the HAKA button). This is especially important because many people end up asking the same questions, and in order to scale everyone needs to work together.
We have daily “SciComp garage” sessions where we provide help in person. Similarly, we have chat that can be used to ask quick questions.
Also, always search this scicomp docs site and old issues in the issue tracker.
Please, don’t send us personal email, because it won’t be tracked and might go to the wrong person or someone without time right now. Personal email is also very likely to get lost. For email contact, we have a service email address, but this should only be used for account matters. If it affects others (software, usage problems, etc), use the issue tracker, otherwise we will point you there.
Quick reference
Open the Triton quick reference - you don’t need to know what is on it (that is what these tutorials cover), but having it open now and during your work will help you a lot.
What’s next?
The next tutorial is Cluster general background knowledge.