Data storage
Videos
Videos of this topic may be available from one of our kickstart course playlists: 2023, 2022 Summer, 2022 February, 2021 Summer, 2021 February.
These days, computing is as much (or more) about data than the actual computing power. And data is more than number of petabytes: it is so easy to get it unorganized, or stored in such a way that it slows down the computation.
In this tutorial, we go over places to store data on Triton and how to choose between them. The next tutorial tells how to access it remotely.
Abstract
See the Triton quick reference
There are many places to store files since they all make a different trade-off of speed, size, and backups.
We recommend scratch / $WRKDIR (below) for most cases.
We are a standard Linux cluster with these options:
$HOME=/home/$USER: 10GB, backed up, not made largerScratch is large but not backed up:
$WRKDIR=/scratch/work/$USER: Personal work directory/scratch/DEPARTMENT/NAME/: Group-based shared directories (recommended for most work, group leaders can request them)
/tmp: temporary directory, pre-user mounted in jobs and automatically cleaned up./l/: local persistent storage on some group servers$XDG_RUNTIME_DIR: ramfs on login node
See Remote access to data for how to transfer and access the data from other computers.
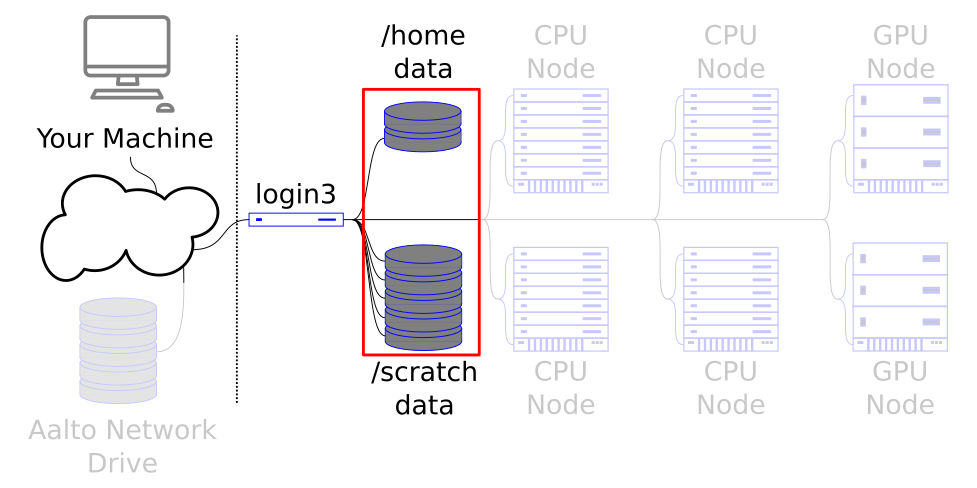
We are now looking at the data storage of a cluster.
Basics
Triton has various ways to store data. Each has a purpose, and when you are dealing with large data sets or intensive I/O, efficiency becomes important.
Roughly, we have small home directories (only for configuration files), large Lustre (scratch and work, large, primary calculation data), and special places for scratch during computations (local disks). At Aalto, there is aalto home, project, and archive directories which, unlike Triton, are backed up but don’t scale to the size of Triton.
Filesystem performance can be measured by both IOPS (input-output
operations per second) and stream I/O speed. /usr/bin/time -v can
give you some hints here. You can see the profiling page for more information.
Think about I/O before you start! - General notes
When people think of computer speed, they usually think of CPU speed. But this is missing an important factor: How fast can data get to the CPU? In many cases, input/output (IO) is the true bottleneck and must be considered just as much as processor speed. In fact, modern computers and especially GPUs are so fast that it becomes very easy for a few GPUs with bad data access patterns to bring the cluster down for everyone.
The solution is similar to how you have to consider memory: There are different types of filesystems with different tradeoffs between speed, size, and performance, and you have to use the right one for the right job. Often times. So you have to use several in tandem: For example, store original data on archive, put your working copy on scratch, and maybe even make a per-calculation copy on local disks. Check out wikipedia:Memory Hierarchy and wikipedia:List of interface bit rates.
The following factors are useful to consider:
How much I/O are you doing in the first place? Do you continually re-read the same data?
What’s the pattern of your I/O and which filesystem is best for it? If you read all at once, scratch is fine. But if there are many small files or random access, local disks may help.
Do you write log files/checkpoints more often than is needed?
Some programs use local disk as swap-space. Only turn it on if you know it is reasonable.
There’s a checklist in the storage details page.
Avoid many small files! Use a few big ones instead. (we have a dedicated page on the matter)
Available data storage options
Each storage location has different sizes, speed, types of backups, and availability. You need to balance between these. Most routine work should go into scratch (group directories) or work (personal). Small configuration and similar can go into your home directory.
Name |
Path |
Quota |
Backup |
Locality |
Purpose |
|---|---|---|---|---|---|
Home |
|
hard quota 10GB |
Nightly |
all nodes |
Small user specific files, no calculation data. |
Work |
|
200GB and 1 million files |
x |
all nodes |
Personal working space for every user. Calculation data etc. Quota can be increased on request. |
Scratch |
|
on request |
x |
all nodes |
Department/group specific project directories. |
Local temp |
|
limited by disk size |
x |
single-node |
Primary (and usually fastest) place for single-node calculation data. Removed once user’s jobs are finished on the node. |
Local persistent |
|
varies |
x |
dedicated group servers only |
Local disk persistent storage. On servers purchased for a specific group. Not backed up. |
ramfs (login nodes only) |
|
limited by memory |
x |
single-node |
Ramfs on the login node only, in-memory filesystem |
Home directories
The place you start when you log in. Home directory should be used for init files, small config files, etc. It is however not suitable for storing calculation data. Home directories are backed up daily. You usually want to use scratch instead.
scratch and work: Lustre
Scratch is the big, high-performance, 2PB Triton storage. It is the primary
place for calculations, data analyzes etc. It is not backed up but is
reliable against hardware failures (RAID6, redundant servers), but
not safe against human error.. It is
shared on all nodes, and has very fast access. It is divided into two
parts, scratch (by groups) and work (per-user). In general, always
change to $WRKDIR or a group scratch directory when you first
log in and start doing work. (note: home and work may be deleted six
months after your account expires: use a group-based space instead).
Lustre separates metadata and contents onto separate object and metadata servers. This allows fast access to large files, but induces a larger overhead than normal filesystems. See our small files page for more information.
Local disks
Local disks are on each node separately. It is used for the fastest I/Os
with single-node jobs and is cleaned up after job is finished. Since 2019,
things have gotten a bit more complicated given that our newest (skl) nodes
don’t have local disks. If you want to ensure you have local storage,
submit your job with --gres=spindle.
See the Compute node local drives page for further details and script examples.
ramfs - fast and highly temporary storage
On login nodes only,
$XDG_RUNTIME_DIR is a ramfs, which means that it looks like files
but is stored only in memory. Because of this, it is extremely fast,
but has no persistence whatsoever. Use it if you have to make small
temporary files that don’t need to last long. Note that this is no
different than just holding the data in memory, if you can hold in
memory that’s better.
Other Aalto data storage locations
Aalto has other non-Triton data storage locations available. See Filesystem details and Science-IT department data principles for more info.
Quotas
All directories under /scratch (as well as /home) have quotas. Two
quotas are set per-filesystem: disk space and file number. Quotas
exist not because we need to limit space, but because we need to make
people think before using large amounts of space. Ask us if you need more.
Disk quota and current usage are printed with the command quota.
‘space’ is for the disk space and ‘files’ for the total number of files
limit. There is a separate quota for groups on which the user is a
member.
$ quota
User quotas for darstr1
Filesystem space quota limit grace files quota limit grace
/home 484M 977M 1075M 10264 0 0
/scratch 3237G 200G 210G - 158M 1M 1M -
Group quotas
Filesystem group space quota limit grace files quota limit grace
/scratch domain users 132G 10M 10M - 310M 5000 5000 -
/scratch some-group 534G 524G 524G - 7534 1000M 1000M -
/scratch other-group 16T 20T 20T - 1088M 5M 5M -
If you get a quota error, see the quotas page for a solution.
Remote access
The next tutorial, Remote access to data, covers accessing the data from your own computer.
Exercises
Most of these exercises will be specific to your local site. Use this time to review your local guides to see how they are adapted to your site.
Data storage locations:
Storage-1: Review data storage locations
(Optional) Look at the list of data storage locations above. Also look at the Filesystem details. Which do you think are suitable for your work? Do you need to share with others?
Storage-2: Your group’s data storage locations
Ask your group what they use and if you can use that, too.
Misc:
Storage-3: Common errors
What do all of the following have in common?
A job is submitted but fails with no output or messages.
I can’t start a Jupyter server on jupyter.triton.
Some files are randomly empty. Or the file had content, I tried to save it again, and now it’s empty!
I can’t log in.
I can log in with ssh, but
ssh -Xdoesn’t work for graphical programs.I get an error message about corruption, such as
InvalidArchiveError("Error with archive ... You probably need to delete and re-download or re-create this file.I can’t install my own Python/R/etc libraries.
Solution
All of these can be caused by exceeding the quota.
(don’t worry, “can’t log in” doesn’t apply to basic ssh login, so you can always still fix it yourself)
About filesystem performance:
strace is a command which tracks system calls, basically the
number of times the operating system has to do something. It can be
used as a rudimentary way to see how much I/O load there is.
Storage-4: strace and I/O operations
Use strace -c to compare the number of system calls in ls,
ls -l, on a directory with many files. On Triton, you can use
the directory /scratch/scip/lustre_2017/many-files/ as a place
with many files in it. How many system calls per file were there
for each option?
Solution
Running strace -c ls /scratch/scip/lustre_2017/many-files/ shows you
that ls took 171 system calls to get the information. By comparison,
ls -l takes 5210 system calls due to all the additional information
it gives. This might not matter in normal situation, but these system calls
can quickly pile up if used in a script.
Storage-5: strace and time
Using strace -c, compare the times of find and lfs find
on the directory mentioned above. Why is it different?
(advanced) Storage-6: Benchmarking
(this exercise requires slurm knowledge from future tutorials and also other slurm knowledge).
Clone the https://github.com/AaltoSciComp/hpc-examples/ git
repository to your personal work directory. Change to the io
directory. Create a temporary directory and…
Run
create_iodata.shto make some data files indata/Compare the IO operations of
findandlfs findon this directory.use the
iotest.shscript to do some basic analysis. How long does it take? Submit it as a slurm batch job.Modify the iotest.sh script to copy the
data/directory to local storage, do the operations, then remove the data. Compare to previous strategy.Use
tarto compress the data while it is on lustre. Unpack this tar archive to local storage, do the operations, then remove. Compare to previous strategies.
What’s next?
See also
If you are doing heavy I/O: Storage
The next tutorial is about remote data access.